12. Anhang: Unicode#
12.1. Kodierung von Schriftzeichen#
Auch Schriftzeichen müssen im Computer binär kodiert werden. Zwar sind schon bei Zahlen verschiedene Codierungsarten denkbar, aber grundlegende Aspekte des Codes ergeben sich durch die Verwendung des Dualsystems in natürlicher Weise. Bei Schriftzeichen ist dies dagegen überhaupt nicht der Fall, schon gar nicht, wenn man sich von der angelsächsischen Sicht löst. Schon im europäischen Sprachraum treten Modifikationen des lateinischen Alphabets mit Akzenten und Umlauten auf, und natürlich gibt es weltweit eine Vielzahl von Schriftsystemen, die in Gebrauch sind oder im Gebrauch waren, so dass eine konsistente Kodierung über alle Grenzen hinweg eine große Herausforderung darstellt.
Historisch mussten die ersten Kodierungen von Schriftzeichen zur maschinellen Verarbeitung zudem auf die mechanische Stabilität von Lochkarten, wie die in Abb. 12.1 gezeigte aus den späten 70er Jahren des letzten Jahrhunderts, Rücksicht nehmen. Entsprechend wurden im Lauf der Zeit eine Vielzahl unterschiedlicher Kodierungen entwickelt [1], die durch Inkompatibilitäten den Informationsaustausch erschwerten. Erst in jüngerer Zeit setzt sich mit Unicode ein umfassender Standard weitgehend durch, der auch in Python seit der Version 3 konsequent unterstützt wird.

Abb. 12.1 Lochkarte in einer auf der Codierung des Lochkartenlochermodells 026 von IBM
basierenden Codierung von Control Data Cooperation. Die dargestellte Lochkarte
enthält eine Zeile aus einem Fortran-Programm mit dem Inhalt ˽˽˽30˽IZ(J)=IZ(J+1)
(Quelle: Gert-Ludwig Ingold).#
Bereits 1967 wurde der American Standard Code for Information Interchange (ASCII) als Standard veröffentlicht, der heute noch eine wichtige Rolle spielt. Auf Großrechnern waren damals aber auch andere Kodierungen in Gebrauch. Der ASCII ist ein 7-Bit-Code und kann somit 128 Zeichen darstellen, die in Abb. 12.4 als Teil des Unicode-Standards gezeigt sind. Die grau unterlegten Akronyme stellen Steuerzeichen dar, wobei SP ein Leerzeichen bezeichnet und damit auch zu den druckbaren Zeichen gerechnet werden kann.
Einige heute noch wichtige Steuerzeichen sind in Tab. 12.1 aufgelistet. Ihnen ist ihr Ursprung in der Zeit der Fernschreiber deutlich anzumerken. Dabei wurde die Übertragung auf Computer von verschiedenen Betriebssystemen nicht einheitlich gehandhabt, was sich zum Beispiel daran zeigt, dass unterschiedliche Varianten mit LF und/oder CR in Gebrauch kamen, um einen Zeilenumbruch anzuzeigen.
Hexcode |
Kürzel |
Bedeutung |
Tastenkombination |
Escape-Sequenz |
|---|---|---|---|---|
08 |
BS |
backspace |
STRG-H |
|
09 |
HT |
horizontal tabulation |
STRG-I |
|
0A |
LF |
line feed (neue Zeile) |
STRG-J |
|
0C |
FF |
form feed (neue Seite) |
STRG-L |
|
0D |
CR |
carriage return (Wagenrücklauf) |
STRG-M |
|
1B |
ESC |
escape |
STRG-[ |
Aus deutschsprachiger Sicht fällt bei der Betrachtung der ASCII-Codetabelle in Abb. 12.4 sofort das Fehlen von Umlauten auf. In einem ersten Schritt liegt daher eine Erweiterung auf einen 8-Bit-Code nahe, der auch weitere Zeichen aus dem europäischen Sprachraum aufnehmen kann. Hierfür existieren eine ganze Reihe von Belegungen, die sich am Bedarf bestimmter Sprachen orientieren.
Von Bedeutung ist unter anderem die Normenfamilie ISO 8859. Für die deutsche
Sprache ist ISO-8859-1, auch bekannt als »Latin-1«, gebräuchlich. Die darin
vorhandenen, über ASCII hinausgehenden Zeichen sind, wenn man die Steuerzeichen
ignoriert, in Abb. 12.5 dargestellt. Auch hier sind wieder
eine Reihe von Steuerzeichen vertreten, unter anderem ein nonbreakable space
(NBSP) und ein soft hyphen (SHY). Der zu den Zeichen gehörige Code ergibt
sich aus den letzten beiden Stellen des Unicode Codepoints, der an dem
vorangestellten U+ erkenntlich ist. Beispielsweise wird das »ä« durch
0xEA kodiert. Da das Eurozeichen in ISO-8859-1 nicht enthalten ist, ist
auch die Norm ISO-8859-15 von Bedeutung, die sich an 8 Stellen von ISO-8859-1
unterscheidet.
In neuerer Zeit hat der Unicode-Standard enorm an
Bedeutung gewonnen, da er das Ziel hat, alle weltweit gebräuchlichen Zeichen zu
kodieren. Hierzu gehören in neuerer Zeit beispielsweise auch
Emoticons. Die aktuelle
Version 16.0 umfasst 154.998
Zeichen und bietet noch genügend Platz für Erweiterungen. Jedes Zeichen ist
einem so genannten Codepoint zugeordnet, der Werte zwischen 0x00 und
0x10FFFF annehmen kann. Da damit jedes Zeichen statt üblicherweise einem
Byte nun drei Byte benötigen würde, werden die Unicode-Zeichen geschickt
kodiert. Für westliche Sprachen ist die Kodierung UTF-8 besonders geeignet, da
die ASCII-Zeichen im Bereich 0x00 bis 0x7F ihre Bedeutung beibehalten.
Wir beschränken uns daher im Folgenden auf die Erklärung dieser Kodierung.
12.2. UTF-8-Kodierung#
Im Unicode-Standard ist jedes Zeichen zunächst einmal mit einer Nummer
versehen, dem Unicode Codepoint, der in
Abb. 12.4‒Abb. 12.7 blau hinterlegt ist und mit
U+ beginnt. In dem darunter befindlichen grünen Feld ist die zugehörige
UTF-8-Kodierung angegeben. Dabei kommen in diesen Beispielen 1-, 2- und
3-Byte-Werte vor. Im Allgemeinen können sogar 4 Bytes auftreten.
Im Bereich 0x00 bis 0x7f wird das letzte Byte des Codepoints
verwendet und auf diese Weise Übereinstimmung mit ASCII erreicht. Somit lassen
sich in einer westlichen Sprache verfasste Texte weitestgehend unabhängig von
der tatsächlichen Kodierung lesen. Außerdem wird die Mehrzahl der vorkommenden
Zeichen platzsparend kodiert. Alle Zeichen, die in mehr als einem Byte kodiert
sind, beginnen in UTF-8 mit einer 1.
Im Bereich 0x0080 bis 0x07FF werden zwei Bytes zur Kodierung verwendet.
Die elf relevanten Bytes aus dem Unicode-Codepoint werden dabei wie in
Abb. 12.2 gezeigt auf die zwei Bytes verteilt. Man kann dieses
Übersetzungsschema natürlich auch umgekehrt anwenden, nachdem man festgestellt
hat, dass der UTF-8-Code mit 0xC beginnt.
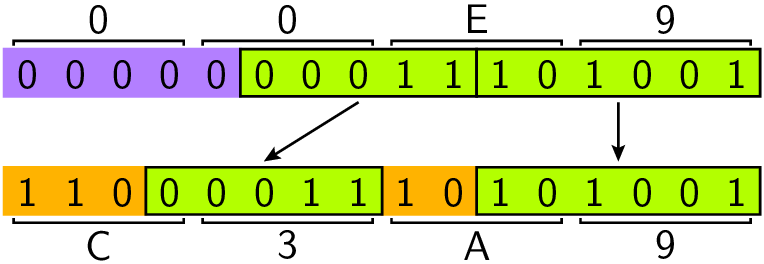
Abb. 12.2 Übersetzung des Unicodezeichens »é«in die UTF-8-Kodierung, die zwei Bytes
benötigt. Dabei wird der Codepoint 0xE9 nach dem gezeigten Schema auf
den UTF-8-Code 0xC3A9 abgebildet.#
Frage
Was würde ein Programm, das von einer Latin-1-Kodierung ausgeht, im Fall des
in Abb. 12.2 gezeigten UTF-8-Codes 0xC3A9 anzeigen.
Beispiele von 2-Byte-Codes sind in den Codetabellen in Abb. 12.5 und Abb. 12.6 zu sehen. Dabei handelt es sich zum einen um die oberen 128 Zeichen der ISO-8859-1-Norm und zum anderen um griechische und koptische Zeichen im Unicode-Standard.
Die in Abb. 12.7 gezeigten mathematischen Symbole erfordern
einen 3-Byte-Code, der sich wie in Abb. 12.7 für das Zeichen
»∞« gezeigt aus dem Unicode-Codepoint ergibt. In der UTF-8-Kodierung sind
3-Byte-Codes daran erkennbar, dass sie mit 0xE beginnen.
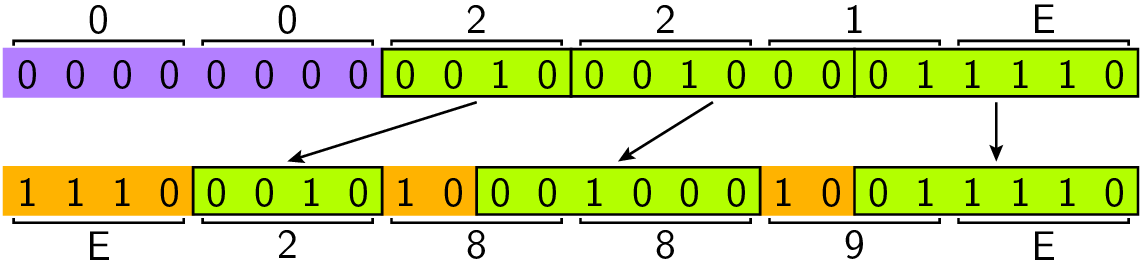
Abb. 12.3 Übersetzung des Unicodezeichens »∞« in die UTF-8-Kodierung, die drei Byte erfordert..#
Aus 4 Bytes bestehende Codes ergeben sich durch entsprechende Verallgemeinerung
für Codepoints zwischen 0x010000 und 0x10FFFF, wobei der UTF-8-Code dann
mit 0xF beginnt.
12.3. Ausgewählte Codeseiten aus dem Unicode-Standard#
Die im Folgenden abgebildeten exemplarischen Codeseiten geben einen kleinen Eindruck von der Vielfalt der vorhandenen Zeichen. Neben den im westlichen Sprachraum häufig verbreiten Zeichen, die in Abb. 12.4 und Abb. 12.5 gezeigt sind, werden als Beispiele in Abb. 12.6 griechische und koptische Zeichen sowie in Abb. 12.7 mathematische Symbole gezeigt. Einen vollständigen Überblick geben die Unicode Character Code Charts.
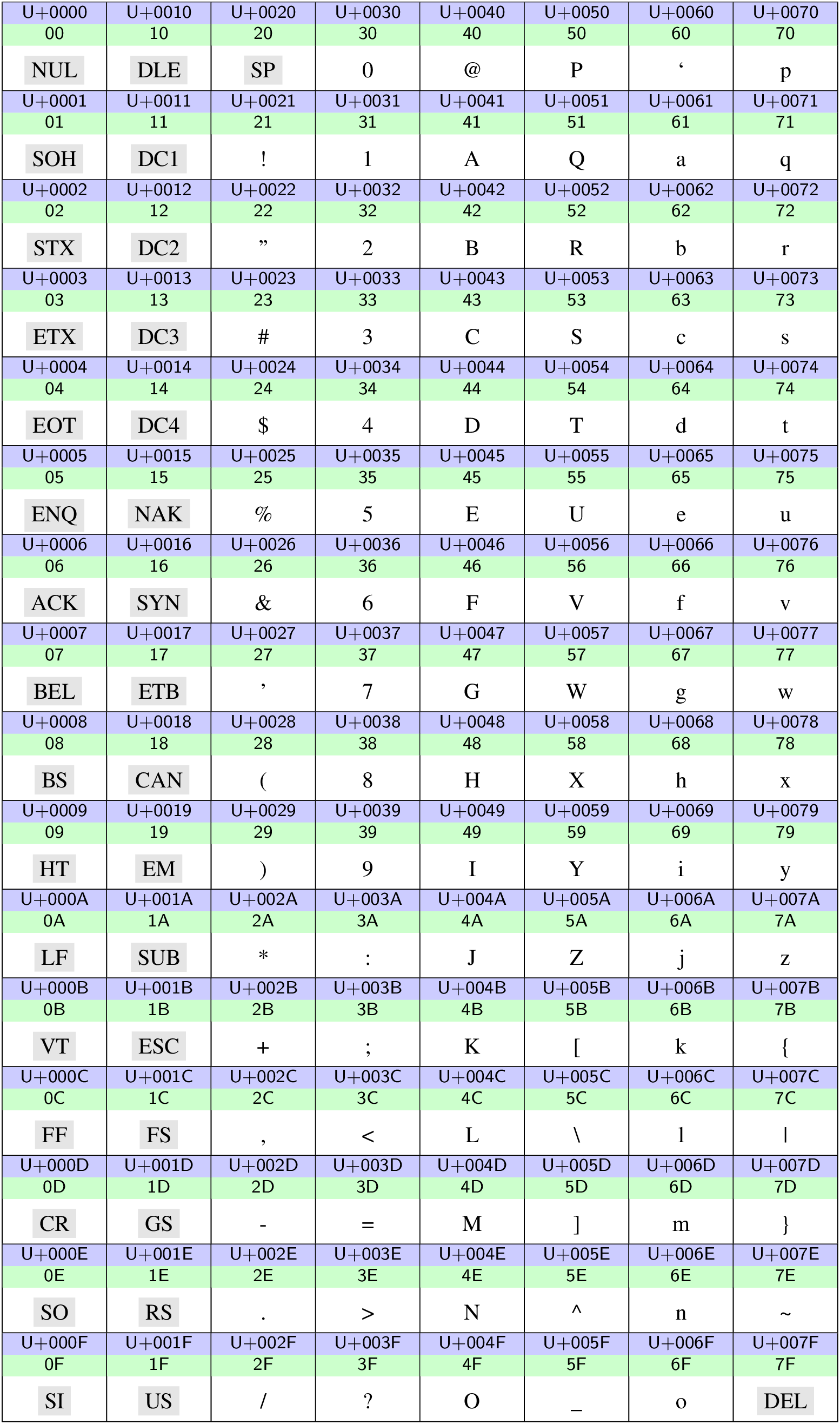
Abb. 12.4 Unicodezeichen im Bereich 0000‒007F. Der Unicode Codepoint sowie die UTF-8-Kodierung sind für jedes Zeichen blau bzw. grün hinterlegt angegeben. Steuerzeichen sind grau hinterlegt.#
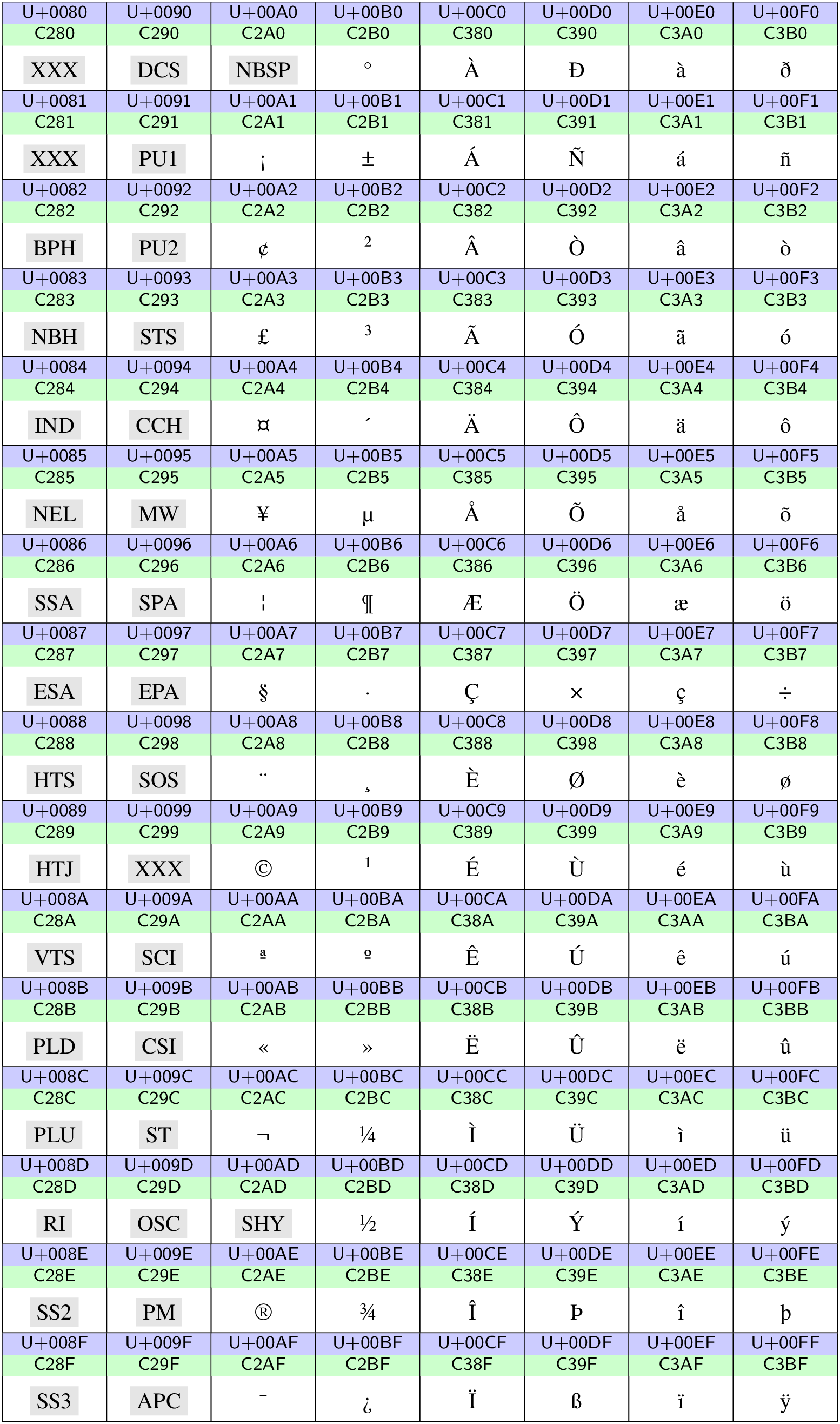
Abb. 12.5 Unicodezeichen im Bereich 0080‒00FF. Der Unicode Codepoint sowie die UTF-8-Kodierung sind für jedes Zeichen blau bzw. grün hinterlegt angegeben. Steuerzeichen sind grau hinterlegt.#
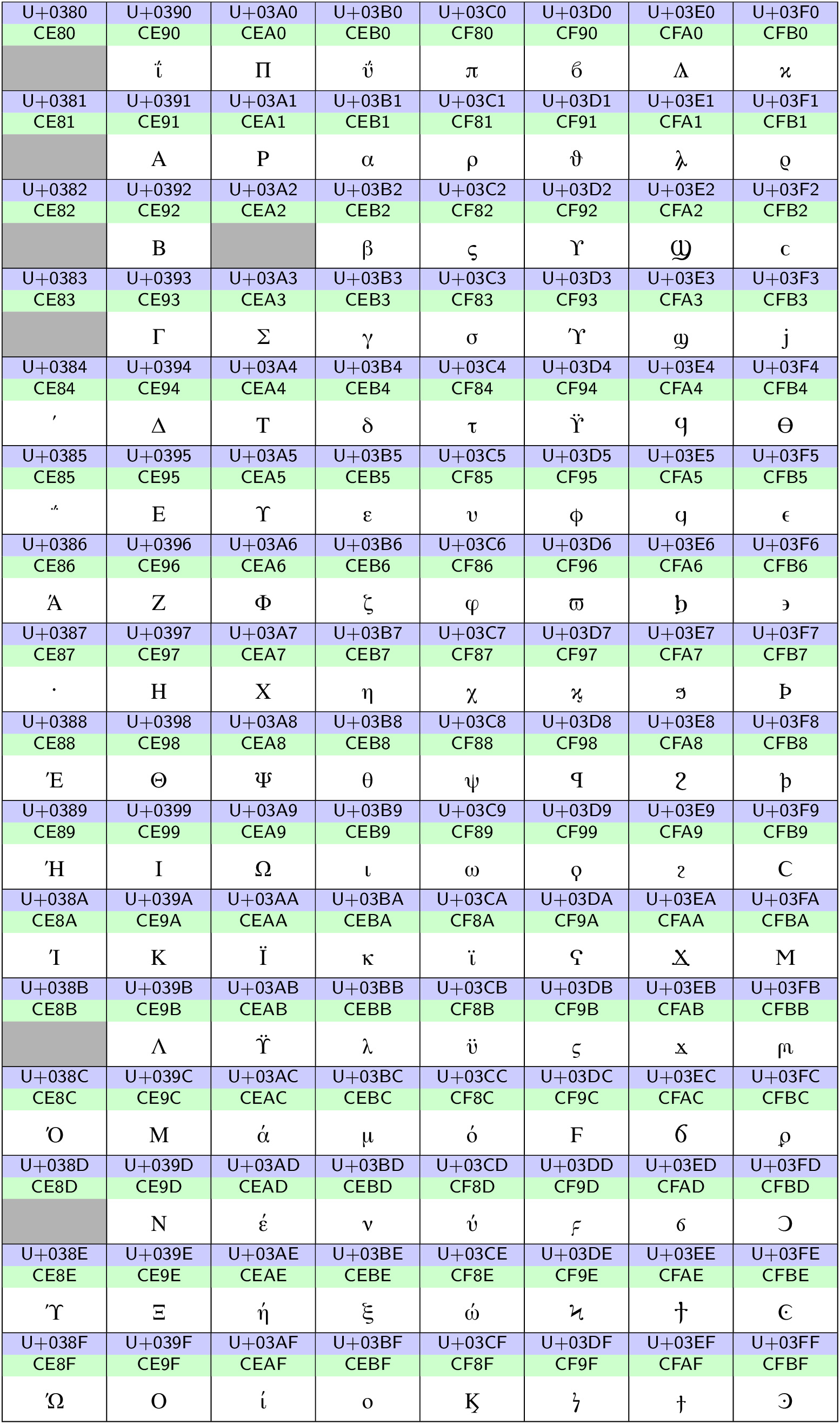
Abb. 12.6 Unicodezeichen im Bereich 0380‒03FF. Der Unicode Codepoint sowie die UTF-8-Kodierung sind für jedes Zeichen blau bzw. grün hinterlegt angegeben. Die grau hinterlegten Einträge sind derzeit nicht mit einem Zeichen belegt.#
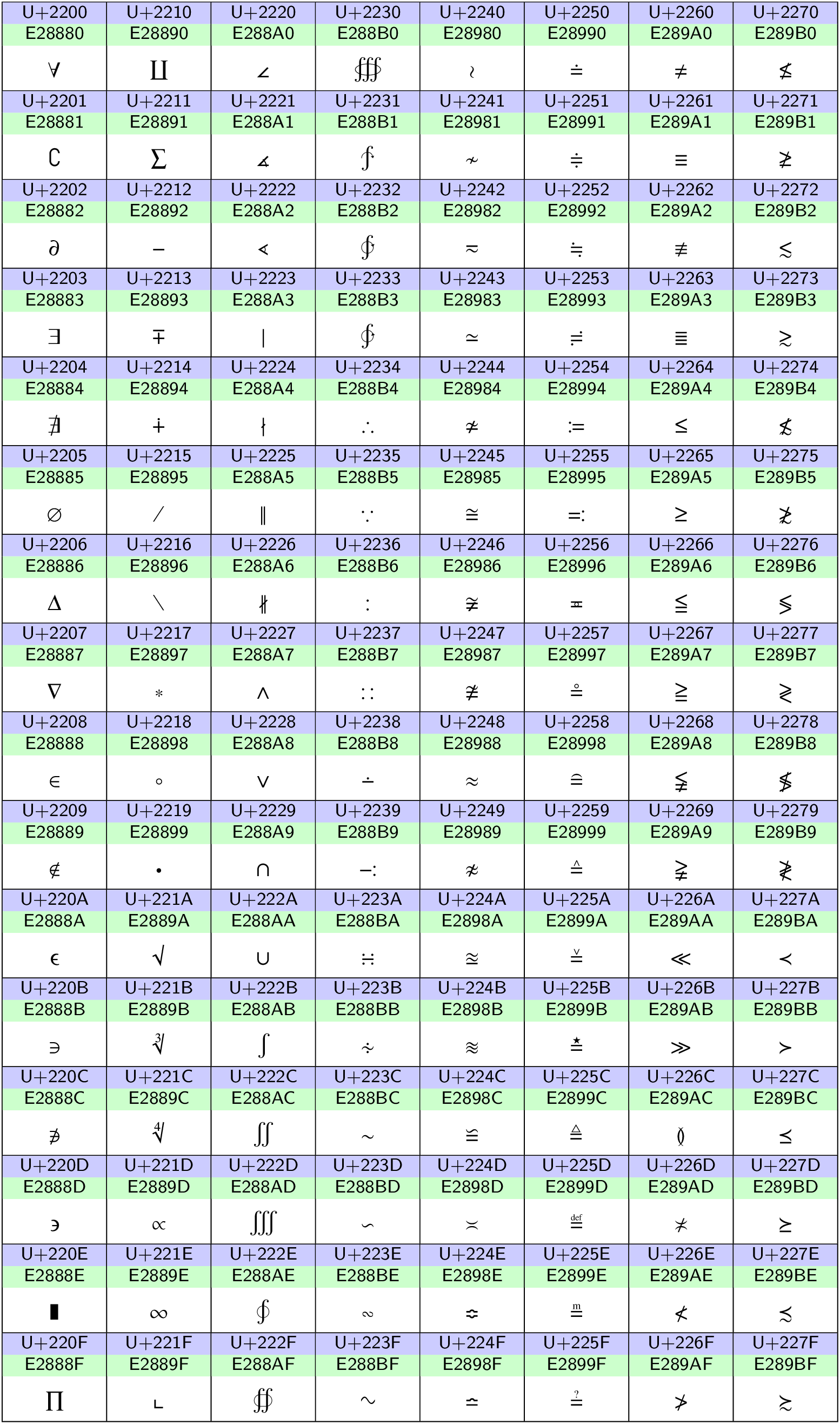
Abb. 12.7 Unicodezeichen im Bereich 2200‒227F. Der Unicode Codepoint sowie die UTF-8-Kodierung sind für jedes Zeichen blau bzw. grün hinterlegt angegeben.#