6. Zusammengesetzte Datentypen#
6.1. Listen#
Bei der Lösung numerischer Probleme spielen die Zahlentypen, die wir im Kapitel 3 kennengelernt haben, also Integers, Gleitkommazahlen oder Floats sowie komplexe Zahlen eine zentrale Rolle. Insbesondere in den Natur- und Ingenieurwissenschaften sind diese Daten aber Bestandteile von komplexeren Datentypen wie Vektoren oder Matrizen. Man spricht in diesem Zusammenhang von zusammengesetzten Datentypen, die wir im Folgenden behandeln wollen. Dabei müssen die Bestandteile nicht unbedingt numerischer Natur sein. Ein Beispiel hierfür wären Zeichenketten.
Bei den zusammengesetzten Datentypen ist es sinnvoll, eine Unterscheidung vorzunehmen, die die Art der einzelnen Bestandteile betrifft. In Programmiersprachen wie Fortran oder C kennt man den Datentyp des Arrays, das eine ein- oder mehrdimensionale Ansammlung von Zahlen des gleichen Datentyps umfasst. Jedes Element nimmt im Speicher gleich viel Platz in Anspruch und die aufeinanderfolgende Elemente schließen im Speicher nahtlos aneinander an. Da die Anordnung der Elemente im Speicher immer eindimensional ist, gibt es für die Speicherung mehrdimensionaler Array unterschiedliche Zugänge und tatsächlich unterscheiden sich Fortran und C in dieser Hinsicht. Die homogene Struktur von Arrays hat zur Folge, dass der Ort eines durch einen Index oder auch mehrere Indizes adressierten Elements im Speicher ausgehend von der Startadresse unmittelbar berechnet werden kann. Dadurch kann man sehr effizient auf Elemente des Arrays zugreifen.
In Python dagegen stehen solche homogenen Datenansammlungen in Form von Arrays nicht im Standardsprachumfang zur Verfügung. Sie werden aber durch die Programmbibliothek NumPy, die die Basis für wissenschaftliche Numerik in Python bildet und die wir im Kapitel 8 besprechen werden, bereitgestellt. Python stellt stattdessen standardmäßig den Datentyp einer Liste zur Verfügung, die Objekte verschiedener Datentypen enthalten kann, aber nicht muss. Die größere Flexibilität der Liste gegenüber den Arrays bezahlt man mit einem höheren Aufwand beim Zugriff auf einzelne Elemente. Wir werden im Folgenden Listen als Datentyp in Python besprechen. Viele Aspekte werden wir später auf die von NumPy zur Verfügung gestellten Arrays übertragen können.
Listen sind uns beispielsweise bereits in Kapitel 4.1 begegnet, wo wir die
range()-Funktion verwendet hatten, um einen Schleifenzähler mit Werten zu versorgen.
Dabei werden die benötigten Werte nur bei Bedarf erzeugt. Um alle Werte auf einmal zu
sehen, hatten wir die list()-Funktion verwendet und dabei eine Liste erzeugt.
meine_liste = list(range(20))
print(meine_liste)
print(type(meine_liste))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
<class 'list'>
Mit der zweiten Ausgabezeile wird hier nachgewiesen, dass der Datentyp des Objekts
meine_liste tatsächlich eine Liste ist.
Wenn man die Länge einer Liste nicht kennt, kann man diese mit Hilfe der len()-Funktion
bestimmen.
liste1 = list(range(1, 17, 3))
print(f'Länge der ersten Liste: {len(liste1)} Elemente')
liste2 = ['Stein', 'Papier', 'Schere']
print(f'Länge der zweiten Liste: {len(liste2)} Elemente')
Länge der ersten Liste: 6 Elemente
Länge der zweiten Liste: 3 Elemente
Eine wichtige Eigenschaft von Listen besteht darin, dass man einzelne Listenelement oder auch Ausschnitte aus der Liste adressieren kann und diese auch verändern kann. Wir demonstrieren dies zunächst an einem einzelnen Listenelement.
meine_liste = [1, 17, 3]
print(meine_liste[1])
17
Zu beachten ist hier, dass der Index immer in eckigen Klammern stehen muss.
Das Ergebnis zeigt, dass die Zählung in Python bei 0 beginnt, wie es beispielsweise auch in der Programmiersprache C der Fall ist. Diese Wahl lässt sich dadurch motivieren, dass die Position des ersten Elements einer Liste relativ zum Beginn der Liste im Speicherplatz durch einen Offset von 0 gegeben ist. Man könnte aber auch argumentieren, dass das erste Element durch den Index 1 adressiert werden sollte. Diese Wahl wurde in der Programmiersprache Fortran getroffen. Man muss sich also diesbezüglich informieren, welche Konvention in der verwendeten Programmiersprache gilt.
Eine Veränderung eines Listenelements ist durch eine Zuweisung für das betreffende Listenelement möglich.
meine_liste[1] = 2
print(meine_liste)
[1, 2, 3]
Neben der Möglichkeit, einzelne Listenelemente anzusprechen, ist es auch möglich, mehrere Listenelemente auf einmal zu adressieren. Dabei kann es sich entweder um eine gegebene Anzahl direkt aufeinanderfolgender Listenelemente oder mehrere Listenelemente mit einem festen Abstand handeln. In der folgenden Liste von Primzahlen werden alle Elemente ab Index 1, also ab dem zweiten Element, bis ausschließlich dem Index 5 ausgewählt.
primzahlen = [2, 3, 5, 7, 11, 13, 17, 19, 23]
print(primzahlen[1:5])
[3, 5, 7, 11]
Gerade zu Beginn ist es oft ungewohnt, dass das Element zum zweiten Index nicht Teil der Auswahl ist,
auch wenn wir dies von der range()-Funktion schon gewohnt sind. Man kann sich dieses Verhalten
dadurch veranschaulichen, dass man sich den Index nicht als Nummerierung eines Elements vorstellt, sondern
als Markierung »zwischen« den Listeneinträgen, wie es in Abb. 6.1 gezeigt ist.
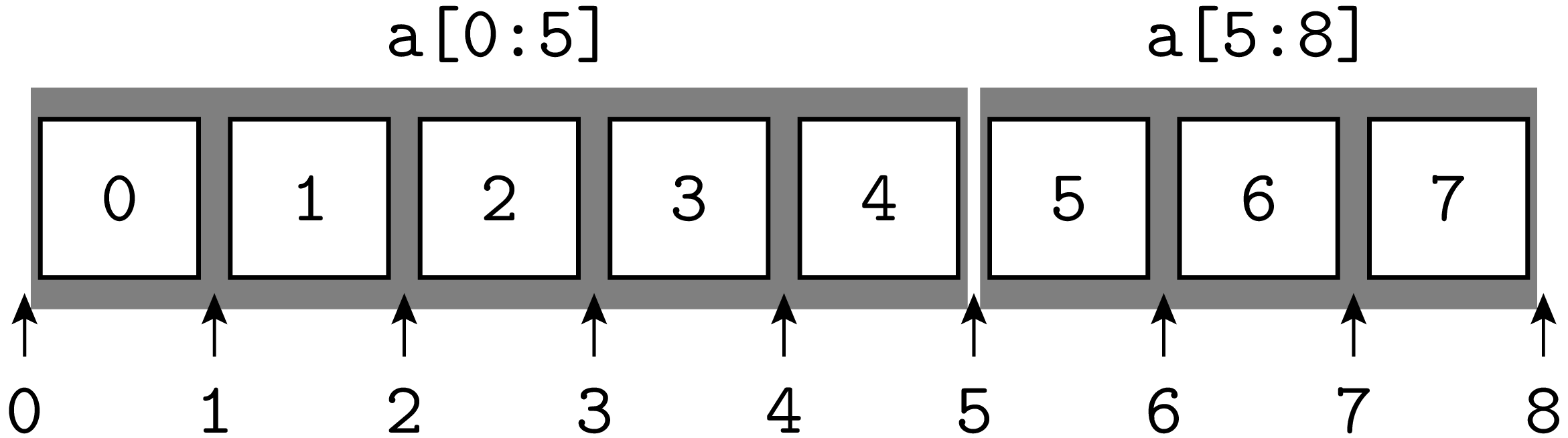
Abb. 6.1 Die Indizierung von Listen lässt sich besser verstehen, wenn man den Index als Markierung »zwischen« den Listeneinträgen versteht.#
Da man in diesem Bild die Liste praktisch wie einen Brotlaib in Scheiben schneidet,
spricht man bei der Adressierung von slices. Wie Abb. 6.1 mit den slices
[0:5] und [5:8] zeigt, ist die von Python benutzte Indizierungskonvention auch
insofern praktisch als aufeinanderfolgende slices den gleichen End -bzw. Anfangsindex
haben.
Wie bei der range()-Funktion gibt es auch bei den slices die Möglichkeit, die
Schrittweite zu wählen. Die Bedeutung der Argumente ist in beiden Fällen gleich, nur dass
in der slice-Notation die Argumente jeweils durch einen Doppelpunkt getrennt sind.
print(primzahlen[1:8:2])
[3, 7, 13, 19]
Hierbei wird aus der obigen Primzahlliste ausgehend vom zweiten Eintrag bis zum achten Eintrag jedes zweite Element ausgewählt.
Wie würde man vorgehen, wenn man ausgehend vom ersten Element jedes dritte Element der Primzahlliste ausgeben möchte. Für die vollständige Indexangabe wird man zunächst einmal die Länge der Liste bestimmen müssen, wenn man diese nicht schon kennt.
print(primzahlen[0:len(primzahlen):3])
[2, 7, 17]
Alternativ kann man aber das Ende der Liste dadurch spezifizieren, dass man den entsprechenden Eintrag leer lässt. Das Fehlen des Index ist dabei anhand der Doppelpunkte erkenntlich.
print(primzahlen[0::3])
[2, 7, 17]
Entsprechend könnten man den ersten Index weglassen.
print(primzahlen[::3])
[2, 7, 17]
Lässt man auch den dritten Index weg, so wird die Schrittweite automatisch auf 1 gesetzt. Statt zwei Doppelpunkten ist es dann aber einfacher, nur einen Doppelpunkt zu setzen. Auf diese Weise erhält man alle Elemente der Liste. Es ist allerdings nicht möglich, alle Doppelpunkte wegzulassen.
print(primzahlen[::])
print(primzahlen[:])
[2, 3, 5, 7, 11, 13, 17, 19, 23]
[2, 3, 5, 7, 11, 13, 17, 19, 23]
Alle Listenelemente kann man zwar auch einfach durch die Angabe des Listennamens ausgeben.
Allerdings werden wir später noch sehen, dass es einen Unterschied macht, ob man nur den
Listennamen verwendet oder ein slice [:].
print(primzahlen)
[2, 3, 5, 7, 11, 13, 17, 19, 23]
Insbesondere wenn die Indizes in einem slice durch Programmcode erzeugt werden, kann es passieren, dass ein Index irrtümlich außerhalb des erlaubten Bereichs liegt. In einer solchen Situation können verschiedene Dinge passieren. Manche Programmiersprachen berechnen, zumindest unter bestimmten Bedingungen, einfach den entsprechenden Ort im Speicher und verwenden die dort vorhandenen Daten, sofern das Programm auf diesen Speicherbereich Zugriffsrechte besitzt. Solche Situationen führen zu Fehlern, die unter Umständen schwer zu identifizieren sind, unter anderem weil das Verhalten in solchen Situationen nicht reproduzierbar sein muss. Normalerweise kann man die betreffenden Programmiersprachen aber dazu zwingen, die Gültigkeit des angegebenen Index zu überprüfen.
Python macht dies immer und so führt ein Zugriff jenseits der oberen Grenze der Liste zu einer Exception.
print(primzahlen[20])
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Cell In[12], line 1
----> 1 print(primzahlen[20])
IndexError: list index out of range
Dagegen sind negative Indizes in einem gewissen Rahmen erlaubt, nämlich von -1 bis -N,
wobei N die Zahl der Listenelemente ist. Die Zuordnung der Listenindizes ist in
Abb. 6.2 dargestellt. Mit negativen Indizes ist es also möglich,
Listenelemente vom Ende her zu adressieren ohne die Länge der Liste kennen zu müssen.
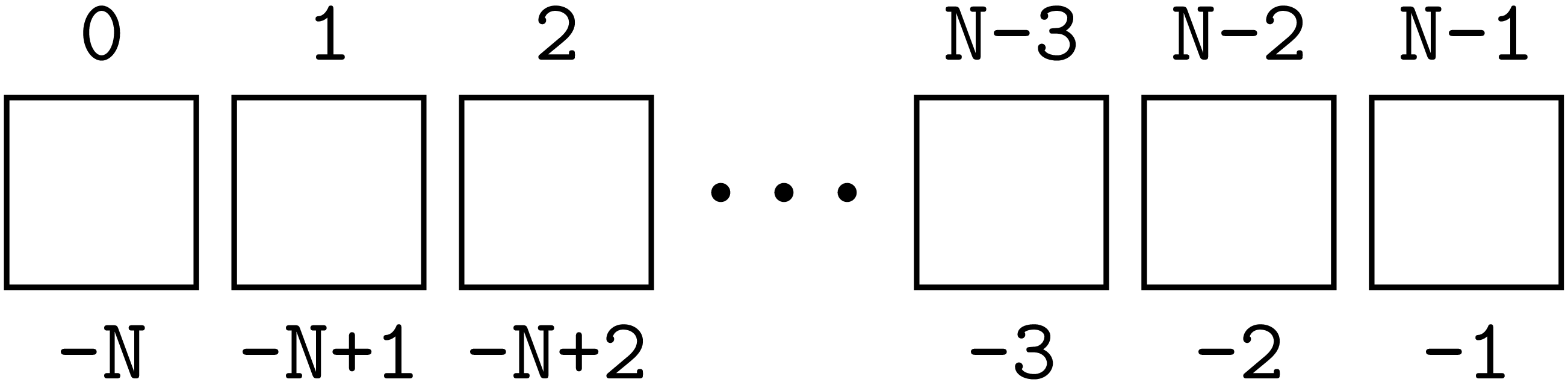
Abb. 6.2 Mit negativen Indizes lassen sich Listenelemente vom Ende der Liste her adressieren.#
So lässt sich beispielsweise sehr leicht das letzte Element einer Liste extrahieren.
print(primzahlen)
print(primzahlen[-1])
[2, 3, 5, 7, 11, 13, 17, 19, 23]
23
Auch die letzten drei Elemente lassen sich auf entsprechende Weise leicht erhalten.
print(primzahlen[-3:])
[17, 19, 23]
Mit einer negativen Schrittweite kann man die Listen in umgekehrter Reihenfolge anordnen.
print(primzahlen[::-1])
[23, 19, 17, 13, 11, 7, 5, 3, 2]
Bei der Arbeit mit Listen in Python ist zu beachten, dass sich diese nicht immer so verhalten, wie man es vielleicht erwarten würde. So erzeugt die Zuweisung einer Liste zu einer anderen Liste nicht zu einer unabhängigen Liste, sondern nur zu einem zweiten Namen, unter dem die ursprüngliche Liste angesprochen werden kann. Man spricht hier auch von einem Alias.
a = [1, 17, 3]
b = a
a[1] = 2
print(a)
print(b)
[1, 2, 3]
[1, 2, 3]
Offenbar wurde hier nicht nur die Liste a verändert. Tatsächlich zeigen die beiden Namen
a und b auf das gleiche Pythonobjekt.
print(id(a), id(b))
139693623023104 139693623023104
Anders sieht es aus, wenn man die Listenelemente zuweist.
a = [1, 17, 3]
b = a[:]
a[1] = 2
print(a)
print(b)
[1, 2, 3]
[1, 17, 3]
Nun handelt es sich bei den beiden Listen in der Tat auch um verschiedene Pythonobjekte.
print(id(a), id(b))
139693623023360 139693623023424
Dieses Verhalten wirkt sich auch aus, wenn man Listen an Funktionen übergibt und innerhalb der Funktion verändert.
def modify_list(x):
x[0] = 2
meine_liste = [1, 2, 3]
modify_list(meine_liste)
print(meine_liste)
[2, 2, 3]
Die vorgenommene Änderung ist also nicht lokal auf die Funktion beschränkt, sondern wirkt sich auf die Liste im Hauptteil aus. Daher sollte man bei der Übergabe von Listen an Funktionen besondere Sorgfalt walten lassen und diese in der Funktion entweder nicht verändern oder zunächst eine Kopie anfertigen.
Wie wir eingangs dieses Kapitels schon besprochen hatten, lassen Listen in Python im Gegensatz zu den homogenen Arrays anderer Programmiersprachen auch unterschiedliche Datentypen als Elemente einer Liste zu. Dies wollen wir an einer Liste demonstrieren, die eine mathematische Aufgabe in einer Liste spezifiziert, indem das erste Element ein Funktionsobjekt enthält während das zweite Element das zugehörige Argument enthält.
from math import sin, pi
aufgabe = [sin, pi/6]
ergebnis = aufgabe[0](aufgabe[1])
print(ergebnis)
0.49999999999999994
Dabei ist die Abweichung vom erwarteten Ergebnis 0.5 durch Rundungsfehler bedingt.
Es ist auch möglich, Listen als Listenelemente zu verwenden.
a = [[1, 2], [3, 4]]
print(a[0])
print(a[1])
print(a[0][1])
[1, 2]
[3, 4]
2
Hier wird beispielsweise mit a[0] das erste Element der Liste a adressiert, also die
Liste [1, 2]. Aus dieser Liste kann wiederum ein Element ausgewählt werden, zum Beispiel
a[0][1].
Auch wenn diese Liste von Listen den Anschein erwecken mag, als Matrix verwendet werden zu können, ist dies nicht wirklich der Fall. Zum einen ist es zwar leicht möglich, einen Zeilenvektor aus der Matrix zu extrahieren, wie wir an unserem Beispiel gesehen haben. Es ist aber nicht möglich, in entsprechender Weise einen Spaltenvektor zu erhalten. Zudem sind keine Matrixoperationen wie zum Beispiel eine Matrixmultiplikation für Listen von Listen definiert. Stattdessen verwendet man für diese Zwecke die Numpy-Arrays, die wir in Kapitel 8 besprechen werden.
Andererseits können Listen in for-Schleifen nützlich sein. So kann man über die
einzelnen Listenelemente der Matrix a iterieren.
for liste in a:
print(liste)
[1, 2]
[3, 4]
Häufig ist es in solchen Fälle sinnvoll, die einzelnen Listenelemente gleich zu entpacken.
for x, y in a:
print(f"{x} * {y} = {x*y}")
1 * 2 = 2
3 * 4 = 12
Wie wir bereits gesehen hatten, können wir Listenelemente verändern. Es ist uns allerdings nicht möglich, auf die gleiche Weise Listenelemente hinzufügen. Das folgende Beispiel kann nicht funktionieren, da versucht wird, auf ein nicht existierendes Listenelement zuzugreifen.
a = [1, 2, 3]
a[3] = 4
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Cell In[25], line 2
1 a = [1, 2, 3]
----> 2 a[3] = 4
IndexError: list assignment index out of range
Es ist jedoch möglich, mit Hilfe der append()-Methode Elemente an eine Liste
anzuhängen.
a = [1, 2, 3]
a.append(4)
print(a)
[1, 2, 3, 4]
Zu beachten ist hier, dass die Liste verändert wird ohne dass eine Zuweisung notwendig
wäre. Würde man das Ergebnis der append()-Methode der Variable a zuweisen, so
würde die Liste mit dem Wert None überschrieben werden.
a = [1, 2, 3]
a = a.append(4)
print(a)
None
Häufig werden im Rahmen einer Schleife mehrere Listenelemente zu einer Liste hinzugefügt.
a = []
for n in range(10):
a.append(n**2)
print(a)
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
In einfacheren Fällen kann eine sogenannte list comprehension eine kompaktere Lösung darstellen.
a = [n**2 for n in range(10)]
print(a)
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
In einer list comprehension lassen sich auch noch Bedingungen stellen, aber man sollte sich davor hüten, solche Konstruktionen zu komplex werden zu lassen.
a = [n**2 for n in range(10) if n % 3]
print(a)
[1, 4, 16, 25, 49, 64]
Die append()-Methode muss von der extend()-Methode unterschieden werden,
mit der eine Liste an eine andere Liste angehängt werden kann. Mit der append-Methode
würde die Liste dagegen ein Element der ersten Liste werden.
a = [1, 2]
b = [3, 4]
a.extend(b)
print(a)
a = [1, 2]
a.append(b)
print(a)
[1, 2, 3, 4]
[1, 2, [3, 4]]
Das Verketten von zwei Listen ist auch mit einem Additionsoperator + möglich. Dagegen
ist es nicht möglich, auf diese Weise ein einzelnes Listenelement hinzuzufügen.
a = [1, 2]
b = [3, 4]
print(a + b)
print(a + 4)
[1, 2, 3, 4]
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[32], line 4
2 b = [3, 4]
3 print(a + b)
----> 4 print(a + 4)
TypeError: can only concatenate list (not "int") to list
Neben der Addition von Listen ist auch die Multiplikation einer Liste mit einer nichtnegativen ganzen Zahl möglich.
a = [1, 2]
print(a*5)
[1, 2, 1, 2, 1, 2, 1, 2, 1, 2]
print(a*0)
[]
b = [0]
print(b*10)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Neben append und extend gibt es noch weitere Methoden, um mit Listen zu arbeiten. Wir
wollen hier nur ein paar Beispiele aufführen und verweisen ansonsten auf die
Python-Dokumentation.
Bei der Suche nach einem bestimmten Wert in einer Liste kann die index()-Methode hilfreich
sein, die den Index des Elements angibt, in dem der gesuchte Wert zum ersten Mal auftritt.
meine_liste = [1, 2, 3, 4, 3, 2, 1]
idx1 = meine_liste.index(2)
print(f"Index: {idx1} Wert: {meine_liste[idx1]}")
Index: 1 Wert: 2
Möchte man die Suche fortsetzen, so muss man darauf achten, sich auf den Teil der Liste nach dem bereits gefundenen Listenelement zu beschränken.
offset = idx1+1
idx2 = meine_liste[offset:].index(2)
print(f"Index: {offset+idx2} Wert: {meine_liste[offset+idx2]}")
Index: 5 Wert: 2
Kommt das gesuchte Element nicht in der Liste vor, so erhält man einen ValueError.
meine_liste.index(5)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[38], line 1
----> 1 meine_liste.index(5)
ValueError: list.index(x): x not in list
Um solche Fälle vernünftig zu behandeln, sollte man die Ausnahme abfangen.
for n in range(7):
try:
print(f"Erstes Auftreten von {n}: {meine_liste.index(n)}")
except ValueError:
print(f"{n} wurde nicht gefunden.")
0 wurde nicht gefunden.
Erstes Auftreten von 1: 0
Erstes Auftreten von 2: 1
Erstes Auftreten von 3: 2
Erstes Auftreten von 4: 3
5 wurde nicht gefunden.
6 wurde nicht gefunden.
Ist man ausschließlich daran interessiert, ob ein Wert in der Liste vorhanden ist, aber
nicht daran, wo sich dieser Wert befindet, so kann man den in-Operator verwenden.
for n in range(7):
if n in meine_liste:
print(f"{n} ist vorhanden")
else:
print(f"{n} ist nicht vorhanden")
0 ist nicht vorhanden
1 ist vorhanden
2 ist vorhanden
3 ist vorhanden
4 ist vorhanden
5 ist nicht vorhanden
6 ist nicht vorhanden
Benötigt man jedoch auch die Position des Eintrags, so sollte man direkt die vorige Variante wählen.
Abschließend sei noch erwähnt, dass man Listen mit Hilfe der sort()-Methode
sortieren kann. Auch dies geschieht in place, es wird also keine neue Liste erzeugt.
from random import randint
zufallsliste = [randint(1, 100) for _ in range(20)]
print(zufallsliste)
zufallsliste.sort()
print(zufallsliste)
[32, 13, 4, 66, 5, 20, 99, 51, 82, 6, 86, 27, 68, 14, 38, 15, 60, 4, 63, 29]
[4, 4, 5, 6, 13, 14, 15, 20, 27, 29, 32, 38, 51, 60, 63, 66, 68, 82, 86, 99]
Bei Bedarf ist es auch möglich, einen Sortierschlüssel anzugeben. Möchte man zum Beispiel nach der letzten Ziffer sortieren, so kann man diese mit einer geeigneten Lambda-Funktion bewerkstelligen.
zufallsliste = [randint(1, 100) for _ in range(20)]
print(zufallsliste)
zufallsliste.sort(key=lambda x: x % 10)
print(zufallsliste)
[35, 32, 58, 81, 71, 36, 66, 60, 51, 92, 19, 81, 96, 75, 63, 29, 18, 4, 9, 61]
[60, 81, 71, 51, 81, 61, 32, 92, 63, 4, 35, 75, 36, 66, 96, 58, 18, 19, 29, 9]
6.2. Tupel#
Tupel sind Listen insofern ähnlich als sie als Elemente Objekte beliebigen Typs enthalten
können. Andererseits sind sie nicht veränderlich. Man sagt auch, dass Listen veränderlich
(mutable) seien, während Tupel unveränderlich (immutable) sind. Dies bedeutet, dass
man auf Elemente von Tupeln mit slices wie bei Listen zugreifen kann. Es ist jedoch
nicht möglich, diese Elemente zu verändern, und es existiert beispielsweise auch keine
append()-Methode, mit der man Elemente an ein Tupel anhängen könnte. Man kann zwar
Tupel mit Hilfe des Additionsoperators aneinanderhängen, was von der Funktionalität an die
extend()-Methode von Listen erinnert.
mytuple1 = (1, 2)
mytuple2 = (3, 4)
print(f'{id(mytuple1) = }')
print(f'{id(mytuple2) = }')
mytuple1 = mytuple1 + mytuple2
print(f'{mytuple1 = }')
print(f'{id(mytuple1) = }')
id(mytuple1) = 139693622925632
id(mytuple2) = 139693623006208
mytuple1 = (1, 2, 3, 4)
id(mytuple1) = 139693623395488
Offensichtlich wird hier ein neues Tupel erzeugt, genauso wie die Verknüpfung zweier
Listen mit Hilfe des Additionsoperators eine neue Liste erzeugen würde. Bei der
extend()-Methode für Listen ist dies dagegen nicht der Fall.
Tipp
Das Zusammenfügen von Tupeln mit Hilfe des Additionsoperators ist ineffizient,
insbesondere wenn es oft geschieht. Je nach Problemstellung ist es daher sinnvoll,
zunächst eine Liste zu erstellen oder die benötigten Elemente mit einem Generatorausdruck
zu erzeugen und anschließend mit Hilfe der tuple()-Funktion ein Tupel zu erzeugen.
Wozu sind Tupel nützlich, wenn sie im Wesentlichen Listen mit eingeschränkter Funktionalität sind? Die Unveränderbarkeit von Tupeln kann in der Praxis nützlich sein. Bei der Besprechung von Listen hatten wir zum Beispiel gesehen, dass besondere Vorsicht bei der Übergabe von Listen an Funktionen geboten ist, wenn innerhalb der Funktion Listenelemente verändert werden, da sich diese Änderungen auch außerhalb der Funktion auswirken. Bei Tupeln ist dies nicht der Fall, so dass sich diese besser für die Übergabe von Daten an eine Funktion eignen. In Kapitel 6.4 werden wir später noch sehen, dass Tupel, im Gegensatz zu Listen, auch als Schlüssel in sogenannten dictionaries Verwendung finden können. Es gibt also gute Gründe, warum es neben den veränderlichen Listen auch noch die unveränderlichen Tupel gibt.
Während Listen durch eckige Klammern eingeschlossen werden, verwendet man für Tupel runde Klammern. Dies ändert jedoch nichts daran, dass bei der Indizierung mit slices eckige Klammern zu verwenden sind.
primzahlen = (2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31)
print(primzahlen[4])
print(primzahlen[1:8:3])
print(primzahlen[::-1])
11
(3, 11, 19)
(31, 29, 23, 19, 17, 13, 11, 7, 5, 3, 2)
Wie schon erwähnt ist es nicht möglich, Einträge in Tupeln zu verändern.
mein_tupel = (1, 17, 3)
mein_tupel[1] = 2
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[45], line 2
1 mein_tupel = (1, 17, 3)
----> 2 mein_tupel[1] = 2
TypeError: 'tuple' object does not support item assignment
Möchte man ein Tupel mit nur einem einzigen Element erzeugen, so muss nach dem ersten Element ein Komma angegeben werden obwohl kein zweites Element folgt. Dies ist erforderlich, da sonst das Objekt den Datentyp des eingeklammerten Elements besitzen würde.
kein_tupel = (1)
print(type(kein_tupel))
ein_tupel = (1,)
print(type(ein_tupel))
<class 'int'>
<class 'tuple'>
Im ersten Fall erhält man also einen Integer und nur im zweiten Fall ein Tupel.
In Kapitel 3.5 und Kapitel 5.1 hatten wir Situationen kennengelernt, in denen
Tupel verwendet werden ohne dass dies durch eine Klammerung explizit ersichtlich ist. Das
folgende Beispiel, das einige Elemente der Fibonacci-Reihe berechnet, enthält in der Funktion
fibonacci_step zwei solche Situationen.
def fibonacci_step(n1, n2):
n1, n2 = n2, n1+n2
return n1, n2
n1 = 0
n2 = 1
for n in range(15):
n1, n2 = fibonacci_step(n1, n2)
print(n2, end=' ')
1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
In der ersten Zeile des Funktionskörpers wird ein Tupel einem anderen Tupel zugewiesen, wobei die einzelnen Werte gleich entpackt werden. In Kapitel 3.5 hatten wir eine entsprechende Konstruktion verwendet, um die Werte zweier Variablen zu vertauschen. Die Rückgabe der beiden Funktionsresultate geschieht letztlich auch mit Hilfe eines Tupels ohne dass eine Klammerung erforderlich wäre.
Die Funktionalitäten, die wir von Listen her kennen und die nicht zu einer Modifikation der Liste führen, existieren auch für Tupel. So können wir beispielsweise die Länge eines Tupels wie von Listen her gewohnt bestimmen.
print(len(primzahlen))
11
Auch lässt sich das Vorhandensein eines Elements in einem Tupel wie schon bei Listen diskutiert überprüfen.
for n in range(1, 10):
if n in primzahlen:
print(f'{n} ist eine Primzahl.')
else:
print(f'{n} ist keine Primzahl.')
1 ist keine Primzahl.
2 ist eine Primzahl.
3 ist eine Primzahl.
4 ist keine Primzahl.
5 ist eine Primzahl.
6 ist keine Primzahl.
7 ist eine Primzahl.
8 ist keine Primzahl.
9 ist keine Primzahl.
Nicht zuletzt können wir auch über Tupel oder gar Tupel von Tupeln iterieren, wobei wir die einzelnen Tupel gleich entpacken können.
from math import hypot
for x, y in ((2, 1), (-2, 4), (3, 0)):
print(f'Abstand des Punktes ({x}, {y}) vom Ursprung: {hypot(x, y):6.3f}')
Abstand des Punktes (2, 1) vom Ursprung: 2.236
Abstand des Punktes (-2, 4) vom Ursprung: 4.472
Abstand des Punktes (3, 0) vom Ursprung: 3.000
6.3. Zeichenketten#
In vielen Beispielen sind wir bereits der Notwendigkeit begegnet, einen Text auszugeben,
der aus einem oder mehreren Zeichen besteht. In einigen Programmiersprachen wird zwischen
einzelnen Zeichen (characters) und Zeichenketten (strings) unterschieden. Dies ist zum
Beispiel in Fortran und C der Fall, wo eine Zeichenkette eine Liste von char darstellt.
In Python gibt es dagegen nur Zeichenketten. Diese bestehen aus einem oder mehreren
Unicodezeichen und sind wie die Tupel, die wir gerade kennengelernt haben, immutable,
also unveränderlich.
Zeichenketten werden in Python wahlweise von Hochkommas (') oder Anführungszeichen (",
aber keine typographischen Anführungszeichen wie “”„‟), wobei am Anfang und am Ende das
gleiche Zeichen verwendet werden muss. Während Python die Art der Begrenzer egal ist, kann
diese Wahl beim Programmieren praktisch sein, wenn das andere Zeichen im Text selbst
vorkommt.
s1 = 'Hallo'
s2 = "Hallo"
s1 == s2
True
Sollte der Begrenzer in der Zeichenkette selbst auch vorkommen, muss ihm mit einem
vorgestellten Backslash (\) die Sonderbedeutung an der betreffenden Stelle genommen
werden.
s = '"God said, \'Let Newton be!\' and all was light" (Alexander Pope)'
print(s)
"God said, 'Let Newton be!' and all was light" (Alexander Pope)
Umgekehrt kann der Backslash auch dazu verwendet werden, um bestimmten Zeichen eine
besondere Bedeutung als Steuerzeichen zu geben. Verwendet man \n, so kann man in der
Ausgabe einen Zeilenumbruch erzeugen.
s = "Eine Zeile\nund noch eine Zeile"
print(s)
Eine Zeile
und noch eine Zeile
Einige weitere Steuerzeichen findet man in Tab. 12.1.
Soll der Backslash nicht dazu dienen, ein Steuerzeichen anzudeuten, muss man seine
Spezialfunktion entweder mit einem weiteren Backshlash außer Kraft setzen oder die
Zeichenkette durch Voranstellen des Zeichens r als raw string kennzeichnen.
s1 = "Eine Zeile\\nund noch eine Zeile"
s2 = r"Eine Zeile\nund noch eine Zeile"
s1, s2
('Eine Zeile\\nund noch eine Zeile', 'Eine Zeile\\nund noch eine Zeile')
Aus der Ausgabe kann man entnehmen, dass beide Varianten für Python vollkommen äquivalent sind.
Wir wir in Kapitel 5.2 gesehen haben, ist es in Python auch möglich,
mehrzeilige Zeichenketten direkt als solche zu definieren. Dazu muss man am Anfang und
am Ende der Zeichenkette statt nur einem Begrenzer, also ' oder ", jeweils drei
dieser Begrenzer setzen.
s = '''Eine Zeile
und noch eine Zeile'''
print(s)
Eine Zeile
und noch eine Zeile
Bei längeren Zeichenketten ist es manchmal auch praktisch, dass Python direkt aufeinanderfolgende Zeichenketten, auch wenn sie über mehrere Zeilen verteilt sind, automatisch zu einer Zeichenkette zusammenfügt, so dass man das nicht selbst explizit tun muss.
s = ('Dies ist eine etwas längere Zeile, '
'die noch weiter geht '
'und noch weiter und noch weiter ...')
print(s)
Dies ist eine etwas längere Zeile, die noch weiter geht und noch weiter und noch weiter ...
Möchte man Zeichen verwenden, die sich nicht ohne Weiteres über die Tastatur eingeben
lassen, so kann man mit dem Steuerzeichen \u den entsprechenden Unicode-Codepoint
angeben oder mit dem Steuerzeichen \N die entsprechende Unicode-Beschreibung.
print('\u263a \N{WHITE SMILING FACE}')
print('\u210f \N{PLANCK CONSTANT OVER TWO PI}')
☺ ☺
ℏ ℏ
Weiterführender Hinweis
Zur Darstellung einer Zeichenkette verwendet Python standardmäßig die UTF8-Kodierung,
was in vielen Fällen die richtige Wahl sein wird. Benötigt man eine andere Kodierung,
so muss je nach Anwendungfall die Kodierung spezifiziert werden oder die
Unicode-Zeichenkette unter Angabe des encoding-Arguments in die entsprechende
Byte-Darstellung umgewandelt werden.
Wie schon eingangs erwähnt, sind Zeichenketten genauso wie Tupel unveränderlich. Man kann Zeichenketten zwar mittels des Additionsoperators verketten, wie wir dies bei Tupeln schon gesehen hatten. Allerdings wird dabei immer eine neue Zeichenkette erzeugt, und dieses Vorgehen ist nicht sonderlich effizient.
s1 = 'Dies ist ein '
s2 = 'Test'
print(f'{id(s1) = } | {id(s2) = }')
s1 = s1 + s2
print(f'{id(s1) = }')
id(s1) = 139693621559536 | id(s2) = 139693745917360
id(s1) = 139693621561136
Ein besseres Verfahren besteht darin, die zusammenzusetzenden Zeichenketten in einer
Liste zu sammeln, und sie anschließend mit der join()-Methode zusammenzufügen.
Dabei handelt es sich um die Methode einer Zeichenkette, die zwischen die in der Liste
aufgeführten Zeichenketten gesetzt wird. Es kann sich dabei um eine leere Zeichenkette
handeln, wenn man die einzelnen Zeichenketten nahtlos aneinander fügen möchte. Im
folgenden Beispiel ist dagegen eine Zeichenkette sinnvoll, die aus einem Leerzeichen
besteht, aber im Prinzip könnte die Zeichenkette auch mehrere Zeichen umfassen.
stringlist = ['Einführung', 'in', 'Prinzipien', 'der', 'Programmierung']
print(''.join(stringlist))
print(' '.join(stringlist))
print('--'.join(stringlist))
EinführunginPrinzipienderProgrammierung
Einführung in Prinzipien der Programmierung
Einführung--in--Prinzipien--der--Programmierung
Neben dem Additionsoperator ist auch der Multiplikationsoperator zwischen einer Zeichenkette und einem Integer definiert ähnlich wie wir das bereits bei Listen gesehen hatten. Die ist beispielsweise praktisch, wenn man in einer Ausgabe einen Trennstrich einer bestimmten Länge setzen möchte.
print('-'*40)
----------------------------------------
Für Zeichenketten gibt es die gleichen Möglichkeiten des slicing, die wir auch von den Tupeln her kennen. Eine Veränderung einzelner oder mehrere Zeichen analog zu den Listen ist dagegen nicht möglich.
s = 'Einführung in Prinzipien der Programmierung'
print(f'{s[14:24] = }')
print(f'{s[-14:] = }')
print(f'{s[1::2] = }')
print(f'{s[::-1] = }')
s[14:24] = 'Prinzipien'
s[-14:] = 'Programmierung'
s[1::2] = 'ifhugi rniindrPormirn'
s[::-1] = 'gnureimmargorP red neipiznirP ni gnurhüfniE'
Wie bei Listen und Tupeln lässt sich auch überprüfen, ob oder wo eine Zeichenkette in einer
anderen Zeichenkette vorhanden ist. Ist die gesuchte Zeichenkette nicht vorhanden, so
erhält man einen ValueError, den man mit einer try…except-Konstruktion behandeln kann,
wie wir in Kapitel 4.4 gesehen hatten.
s = 'Einführung in Prinzipien der Programmierung'
print('in' in s)
print(s.index('in'))
print(s.index('x'))
True
1
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[62], line 4
2 print('in' in s)
3 print(s.index('in'))
----> 4 print(s.index('x'))
ValueError: substring not found
Wie über Listen oder Tupel kann man auch über Zeichenketten iterieren. Man erhält dann nacheinander die einzelnen Zeichen der Zeichenkette.
for c in 'ABC':
print(c)
A
B
C
Python stellt auch eine Reihe von Methoden spezifisch für Zeichenketten zur Verfügung, aus denen wir hier nur eine kleine Auswahl ansprechen wollen. Einen vollständigen Überblick bietet die Dokumentation unter dem Stichwort String Methods.
Häufig steht man vor der Aufgabe, überschüssige Leerzeichen um eine Zeichenkette herum oder
einen Zeilenumbruch am Ende einer Zeichenkette zu entfernen. Die geht mit den Methoden strip()
für beide Seiten, lstrip() für die linke und rstrip() für die rechte Seite der
Zeichenkette. Ohne Argumente werden dabei Leerzeichen entfernt. Alternativ kann man eine Zeichenkette
angeben, die die zu entfernenden Zeichen enthält.
s = ' Hallo '
print(f'|{s.lstrip()}|')
print(f'|{s.rstrip()}|')
print(f'|{s.strip()}|')
|Hallo |
| Hallo|
|Hallo|
s = 'Hallo\n'
print(s)
print('-'*10)
print(s.rstrip('\n'))
print('-'*10)
Hallo
----------
Hallo
----------
Im letzten Beispiel erkennt man den ursprünglich vorhandenen Zeilenumbruch an der Leerzeile in der Ausgabe.
Beim Vergleichen von Zeichenketten kann es nützlich sein, unabhängig von der Groß- und
Kleinschreibung zu sein. Dann helfen die Methoden upper() und lower() weiter.
s = 'Hallo'
print(s.upper(), s.lower())
HALLO hallo
Das abschließende Beispiel demonstriert, wie man einen Bruch formatiert darstellen kann. Die perfekte Ausrichtung funktioniert natürlich nur, wenn beide Zahlen eine gerade oder eine beide eine ungerade Anzahl von Stellen haben.
zaehler = 12345678
nenner = 2468
s_zaehler = str(zaehler)
s_nenner = str(nenner)
maxlaenge = max(len(s_zaehler), len(s_nenner))
print(s_zaehler.center(maxlaenge))
print('-'*maxlaenge)
print(s_nenner.center(maxlaenge))
12345678
--------
2468
6.4. Dictionaries#
Den letzten zusammengesetzten Datentyp, den wir in diesem Kapitel besprechen wollen, sind Dictionaries oder auch hash tables, die Schlüsseln (key) Werte (value) zuordnen. Man kann sich diese Objekte wie Telefonbücher oder Wörterbücher vorstellen, in denen man unter geordneten Schlüsseln schnell den richtigen Eintrag finden kann und dort die gesuchte Information nachschlagen kann.
Betrachten wir ein Beispiel, um eine bessere Vorstellung von Dictionaries zu bekommen. Konkret wollen wir Informationen über die Atommasse einiger Elemente zusammenstellen.
atommasse = {'H': 1.008, 'He': 4.002602, 'Li': 6.94, 'Be': 9.0121831}
atommasse['Li']
6.94
In der ersten Zeile ist zu sehen, wie einem Schlüssel, hier das chemische Symbol, ein Wert, im Beispiel die zugehörige Atommasse, zugeordnet wird. Die zweite Zeile zeigt, wie man den Wert unter Angabe des Schlüssels erhalten kann. Sehen wir uns die beiden Zeilen etwas genauer an. Im Gegensatz zu Listen, deren Einträge durch eckige Klammern begrenzt sind, und Tupeln, die durch runde Klammern eingeschlossen werden, werden für Dictionaries in Python geschweifte Klammern verwendet. Die durch Kommas getrennten Einträge bestehen aus dem bereits erwähnten Paar von Schlüssel und Wert, die durch einen Doppelpunkt getrennt sind.
Welche Objekte sind nun als Schlüssel und Wert zugelassen? Für Schlüssel muss sich ein sogenannter Hashwert berechnen lassen, also eine ganze Zahl, die den Schlüssel charakterisiert. Da sich ein Hashwert nur für unveränderliche Objekte wie numerische Datentypen, Tupel oder Zeichenketten definieren lassen, sind Listen und Dictionaries selbst nicht für Schlüssel zulässig. An dieser Stellen erkennen wir einen Vorteil, den Tupel gegenüber Listen bieten. Andererseits können die Werte sowohl unveränderliche als auch unveränderliche Objekte sein. Das bedeutet zum Beispiel, dass eine Liste ein Wert sein könnte und diese Liste im Programmlauf potentiell auch verändert werden kann. Im Übrigen ist es nicht notwendig, dass alle Schlüssel vom gleichen Datentyp sein müssen und auch für die Werte ist dies nicht erforderlich.
Wie wir gerade schon angedeutet haben, sind Dictionaries veränderbar, also mutable. Zu einem Dictionary kann man weitere Schlüssel-Wert-Paare hinzufügen. Dazu verwendet man wie schon beim Auslesen von Werten in unserem ersten Beispiel eckige Klammern, die den Schlüssel einschließen. Diese Notation ist analog zur Indizierung von Listen mit Hilfe von slices.
atommasse['B'] = 10.81
print(atommasse)
{'H': 1.008, 'He': 4.002602, 'Li': 6.94, 'Be': 9.0121831, 'B': 10.81}
Offenbar ändert sich die Reihenfolge der bisherigen Einträge durch die Hinzufügung nicht. Man darf allerdings nicht davon ausgehen, dass dies auch in anderen Programmiersprachen, die Dictionaries oder entsprechende Datentypen zur Verfügung stellen, auch der Fall ist. Tatsächlich ist dieses Verhalten auch in Python erst seit der Version 3.6 realisiert, die eine neue Implementation von Dictionaries enthielt.
Wenn man versucht, auf den Wert zu einem nicht existierenden Schlüssel zuzugreifen, so erhält
man einen KeyError, den man mit der üblichen try…except-Konstruktion behandeln könnte
atommasse['O']
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[70], line 1
----> 1 atommasse['O']
KeyError: 'O'
Möchte man nur wissen, ob ein Schlüssel im Dictionary vorhanden ist und interessiert man sich nicht für den zugehörigen Wert, kann man folgendermaßen vorgehen.
'B' in atommasse
True
Iteriert man über ein Dictionary, so erhält man die darin enthaltenen Schlüssel.
for k in atommasse:
print(k, end=", ")
H, He, Li, Be, B,
Benötigt man auch die zugehörigen Werte, so kann man die items()-Methode verwenden, die
Tupel aus Schlüssel und zugehörigem Wert liefert. Es ist durchaus üblich, aber nicht zwingend,
die entsprechenden Variablen beim Entpacken des Tupels mit k für key und v für value
zu bezeichnen.
for k, v in atommasse.items():
print(f'{k:2s} | {v:5.2f}')
H | 1.01
He | 4.00
Li | 6.94
Be | 9.01
B | 10.81
Wir wollen hier nicht alle Möglichkeiten im Detail besprechen, die für die Arbeit mit Dictionaries in Python zur Verfügung stehen, sondern verweisen an dieser Stelle auf den entsprechenden Abschnitt in der Python-Dokumentation. Stattdessen wollen wir die Anwendung von Dictionaries an zwei Anwendungsbeispielen demonstrieren und abschließend noch das Versprechen aus Kapitel 4.3 einlösen und zeigen, wie man Dictionaries als Ersatz für Mehrfachverzweigungen verwenden kann.
Im ersten Beispiel wollen wir die Häufigkeiten von Zeichen in einem Text bestimmen.
Die Idee ist, hierzu ein Dictionary zu verwenden, in dem die Zeichen die Schlüssel
bilden und die zugehörigen Werte die Zähler darstellen, die sukzessive hochgezählt
werden. Dazu beginnen wir mit einem leeren Dictionary counter. Bei der Iteration
über die Zeichen des Textes inkrementieren wir immer den entsprechenden Eintrag.
Allerdings wird bei jedem neuen Zeichen ein KeyError auftreten, da der entsprechende
Eintrag noch nicht vorhanden ist. Wir können dieses Problem mit in einer
try…except-Konstruktion behandeln oder aber einfach den Wert zu dem neuen Schlüssel
initialisieren.
text = 'Abrakadabra'
counter = {}
for c in text:
if c not in counter:
counter[c] = 0
counter[c] = counter[c] + 1
occurrences = list(counter.items())
for c, n in sorted(occurrences, key=lambda x: -x[1]):
print(f'{c}: {n}')
a: 4
b: 2
r: 2
A: 1
k: 1
d: 1
Im unteren Teil der Lösung konstruieren wir uns zunächst eine Liste aus Tupeln, die jeweils den Schlüssel und den zugehörigen Wert enthalten. Um in der Ausgabe die häufigsten Buchstaben zuerst auflisten zu können, verwenden wir hier eine Lambda-Funktion, die nach dem zweiten Element des Tuples, also dem Wert im Dictionary, sortiert. Das Minuszeichen sorgt dabei dafür, dass die höheren Wert zuerst kommen.
Weiterführender Hinweis
Die drei Zeilen in der ersten for-Schleife lassen sich in Python einfacher schreiben,
da Werte aus einem Dictionary mit Hilfe der get()-Methode abgefragt werden können,
die es auch erlaubt, einen Defaultwert für den Fall anzugeben, dass der Schlüssel nicht
existiert. In der for-Schleife könnte man also einfach
counter[c] = counter.get(c, 0) + 1
schreiben.
Wenn man öfters Objekte zählen muss, lohnt ein Blick in die Standardbibliothek von
Python. Unter Verwendung des collections-Modul lässt sich unser Beispiel noch
einfacher realisieren.
from collections import Counter
text = "Abrakadabra"
for character, frequency in Counter(text).most_common():
print(f"{character}: {frequency}")
Aber wir wollten ja eigentlich lernen, wie man mit Dictionaries umgeht.
Um die Verwendung von Listen als Werten von Dictionaries zu illustrieren, wollen wir nun
eine Liste von Worten nach ihrer Länge in Gruppen einteilen. Das Vorgehen ist ähnlich
wie im vorigen Beispiel. Allerdings müssen wir hier zunächst den Schlüssel bestimmen
was wir einmal zu Beginn jedes Durchlaufs durch die for-Schleife erledigen. Wie wir
am Ende der Schleife sehen, können wir den neuen Eintrag direkt an die betreffende Liste
im Dictionary anhängen. Es ist also nicht nötig, eine neue Liste zu erzeugen und diese
im Dictionary dem entsprechenden Eintrag zuzuweisen. Die Ausgabe des Dictionaries vereinfachen
wir dadurch, dass wir pprint()-Funktion aus dem pprint-Modul der Standardbibliothek verwenden.
from pprint import pprint
fruechte = ('Apfel', 'Birne', 'Banane', 'Heidelbeere', 'Kirsche', 'Traube')
gruppen = {}
for frucht in fruechte:
key = len(frucht)
if key not in gruppen:
gruppen[key] = []
gruppen[key].append(frucht)
pprint(gruppen)
{5: ['Apfel', 'Birne'],
6: ['Banane', 'Traube'],
7: ['Kirsche'],
11: ['Heidelbeere']}
Weiterführender Hinweis
Auch hier können die letzten drei Zeilen der for-Schleife vereinfacht werden. Hierzu
benötigt man aber die setdefault()-Methode des Dictionaries, die bei einem
fehlenden Schlüssel den entsprechenden Eintrag im Dictionary anlegt und mit dem angegebenen
Defaultwert befüllt. Man könnte also einfacher
gruppen.setdefault(key, []).append(frucht)
schreiben.
In Kapitel 4.3 hatten wir unter anderem die Möglichkeit von Mehrfachverzweigungen
angesprochen, aber auch darauf verwiesen, dass längliche if…elif…else-Konstruktionen
häufig mit Hilfe von Dictionaries vermieden werden können. Damit erhält man in Python
einen Ersatz für case- oder switch-Anweisungen, die in anderen Programmiersprachen
existieren.
Zur Illustration verwenden wir ein konkretes Anwendungsbeispiel für die case-Anweisung
in der Programmiersprache Pascal.
case i of
0: x := 0;
1: x := sin(x);
2: x := cos(x);
3: x := exp(x);
4: x := ln(x);
end
Hierbei wird abhängig vom Wert des Integers i eine von verschiedenen mathematischen
Funktionen ausgeführt. Diese Problemstellung könnten wir in Python mit einer if…elif-Konstruktion
realisieren. Besser ist aber die Lösung mit Hilfe eines Dictionaries, wobei als Schlüssel
die Zahlen 0 bis 4 verwendet werden und die zugehörigen Werte die gewünschten Funktionen sind.
from math import cos, exp, log, sin
funktion = {0: lambda x: 0,
1: sin,
2: cos,
3: exp,
4: log}
x = 2
for i in range(5):
print(funktion[i](x))
0
0.9092974268256817
-0.4161468365471424
7.38905609893065
0.6931471805599453
Hier haben wir ausgenutzt, dass Funktionen in Python Bürger erster Klasse sind,
die somit auch als Werte in Dictionaries in Frage kommen. Außerdem haben wir es
im ersten Eintrag des Dictionaries mit einer Lambda-Funktion vermieden, extra
eine Funktion zu definieren, die nichts anderes tut als den Wert Null
zurückzugeben. Betrachten wir noch die letzte Zeile, die auf den ersten Blick
vielleicht etwas verwirrend aussieht. Hier wird mit funktion[i] zunächst das
benötigte Funktionsobjekt beschafft, wobei die Variable i den entsprechenden
Schlüssel enthält. Diese Funktion kann nun in der üblichen Weise aufgerufen werden,
womit sich der Funktionsaufruf funktion[i](x) erklärt.